TypeError: transpose() received an invalid combination of arguments - got (int, int, int, int), but
TypeError: transpose() received an invalid combination of arguments - got (int, int, int, int), but expected one of:
*(int dim0, int dim1)
*(name dim0, name dim1)
UserWarning: mkl-service package failed to import, therefore Intel(R) MKL initialization ensuring its correct out-of-the box operation under condition when Gnu OpenMP had already been loaded by Python process is not assured. Please install mkl-service package
出现这个问题,是由于这个whl和系统python版本不匹配导致的。这个时候,需要我们找到当前python版本需要的whl命名格式,网上有不少教程提供了查看python支持whl名称的方法。 然而,网上的教程非常老旧,按照网上教程操作后,会提示pip has no attribute pep425tags。经过我多次搜集资料和尝试,总算找到了在pip 20.0等版本上可用的命令!
Collecting opencv-python
Downloading https://files.pythonhosted.org/packages/77/f5/49f034f8d109efcf9b7e98fbc051878b83b2f02a1c73f92bbd37f317288e/opencv-python-4.4.0.42.tar.gz (88.9MB)
100% |████████████████████████████████| 88.9MB 919kB/s
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing wheel metadata ... done
Requirement already satisfied: numpy>=1.13.1 in /usr/local/lib/python3.5/dist-packages (from opencv-python) (1.14.5)
Building wheels for collected packages: opencv-python
Building wheel for opencv-python (PEP 517) ...
sudo ./install.sh
$ clinfo
Number of platforms 1
Platform Name Intel(R) CPU Runtime for OpenCL(TM) Applications
Platform Vendor Intel(R) Corporation
Platform Version OpenCL 2.1 LINUX
Platform Profile FULL_PROFILE
Platform Extensions cl_khr_icd cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_byte_addressable_store cl_khr_depth_images cl_khr_3d_image_writes cl_intel_exec_by_local_thread cl_khr_spir cl_khr_fp64 cl_khr_image2d_from_buffer cl_intel_vec_len_hint
Platform Host timer resolution 1ns
Platform Extensions function suffix INTEL
Platform Name Intel(R) CPU Runtime for OpenCL(TM) Applications
Number of devices 1
Device Name Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz
Device Vendor Intel(R) Corporation
Device Vendor ID 0x8086
Device Version OpenCL 2.1 (Build 0)
Driver Version 18.1.0.0920
Device OpenCL C Version OpenCL C 2.0
Device Type CPU
Device Profile FULL_PROFILE
Device Available Yes
Compiler Available Yes
Linker Available Yes
Max compute units 8
Max clock frequency 3400MHz
Device Partition (core)
Max number of sub-devices 8
Supported partition types by counts, equally, by names (Intel)
Max work item dimensions 3
Max work item sizes 8192x8192x8192
Max work group size 8192
Preferred work group size multiple 128
Max sub-groups per work group 1
.....
Global 64 bytes
Local 0 bytes
Max size for global variable 65536 (64KiB)
Preferred total size of global vars 65536 (64KiB)
Global Memory cache type Read/Write
.........






 出现这个问题首先看一下你当前所用的conda环境是不是你当前用的环境。
在pycharm的terminal终端默认用的是base环境,需要通过activate命令激活到你所用的环境,再通过tensorboard命令看运行记录。
出现这个问题首先看一下你当前所用的conda环境是不是你当前用的环境。
在pycharm的terminal终端默认用的是base环境,需要通过activate命令激活到你所用的环境,再通过tensorboard命令看运行记录。
 在这时你可能会遇到一个问题,在pycharm的terminal终端通过activate命令激活时无法激活到对应环境。
这时问题很好处理。 转到File -> Settings -> Tools -> Terminal。
在这时你可能会遇到一个问题,在pycharm的terminal终端通过activate命令激活时无法激活到对应环境。
这时问题很好处理。 转到File -> Settings -> Tools -> Terminal。

 然后保存之后关闭pycharm重新打开 activate命令就可以使用了
然后保存之后关闭pycharm重新打开 activate命令就可以使用了 然后激活到你对应的conda环境输入tensorboard命令就ok了
然后激活到你对应的conda环境输入tensorboard命令就ok了 
 解决方法:找到对应的文件路径,发现在sit-packages文件夹下面有几个名称前面带有“~”标识的文件夹,将其手动删除即可:
解决方法:找到对应的文件路径,发现在sit-packages文件夹下面有几个名称前面带有“~”标识的文件夹,将其手动删除即可: 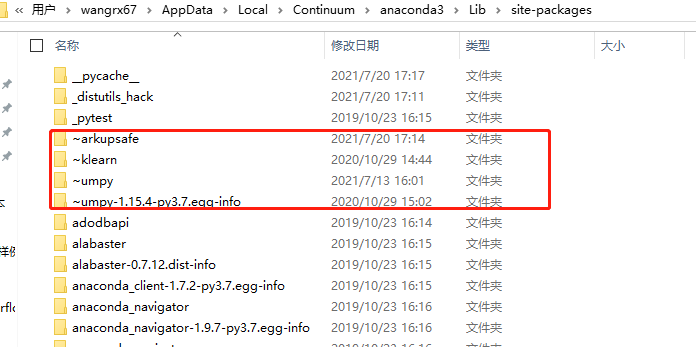
 根据最后一行红色字体我们知道出现了MemoryError,根据字面意思我们可知此问题与内存有关。
根据最后一行红色字体我们知道出现了MemoryError,根据字面意思我们可知此问题与内存有关。









